Sistemas Operativos: Abstracción del Hardware, Concurrencia, Middleware y Más Allá

Estoy leyendo este libro sobre sistemas operativos y me parecio interesante - aunque queden como notas personales- resumir un poco las ensenianzas.
Un sistema operativo es software que utiliza hardware como recurso para dar soporte para la ejecucion de otro software.
Especificamente:
- El sistema operativo permite que se lleven multiples tareas computacionales a la vez. Divide el tiempo de uso del hardware para cada tarea y cambia el foco entre ellas llevando un registro de a donde y como se dejo cada una para luego retomarla.
- El sistema operativo tambien controla la interaccion entre tareas que corren en simultaneo. A su vez puede establecer reglas, como la prohibicion de modificar estructuras de datos mientras otros softwares tratan de acceder a estas. Tambien puede proveer espacios aislados de memoria para uso privado de ciertas tareas.
- El sistema operativo puede tambien dar soporte para la interaccion controlada de tareas incluso cuando no corran de manera concurrente, en particular algunos sistemas operativos ofrecen sistemas de archivos lo cual permiten a las tareas leer y escribir sobre lo que hicieron tareas anteriores. Es opcional dado que por ejemplo un sistema operativo de una lavadora de ropas puede no necesitar uno de estos
- El sistema operativo tambien puede brindar soporte para la interaccion controlada de tareas distribuidas en distintos sistemas a traves del networking (las redes)
Cuando pensamos en sistemas operativos, pensamos en Mac, Linux o Windows, pero los sistemas embebidos por ejemplo pueden tener sistemas operativos dedicados a realizar una sola tarea. Los sistemas mas simples ejecutan un solo programa directamente con el procesador, ese programa lee instrucciones de entradas como sensores, llevan a cabo computos y escriben el output.
Una definicion tambien de un sistema operativo, es que es software que provee una abstraccion del hardware en el cual opera, haciendose cargo de los detalles de bajo nivel para que las applicaciones puedan ser programadas de manera mas facil.
Una percepcion del usuario es que el sistema operativo es lo que vemos de forma grafica en nuestro monitor y utilizamos para abrir programas y llevar acabo tareas, lo que nos permite hacer click y abrir distintas aplicaciones. Hay un poco de verdad en esa percepcion, el sistema operativo brinda el servicio de ejecutar distintas aplicaciones. De todas maneras, el sistema operativo le brinda esta posibilidad no al humano que anda clickeando por ahi, sino tambien a otros programas que ya estan corriendo en la computadora, incluyendo al programa que muestra los iconos y el que maneja los clicks del usuario. La suma de estas interfaces que provee el sistema operativo para que los progamadores puedan usar en sus programas se llama API, application programming interface.
La razon por la cual podemos hacer click en el icono de un programa para correrlo es que los sistemas operativos de uso general incluyen un programa de interfaz grafica, el cual utiliza la API del sistema operativo para correr otros porogramas en respuesta al click de un mouse o el accionar de un teclado.
Tomando microsoft windows como ejemplo, este viene con una interface llamada File Explorer, el cual nos da features como el menu start, la habilidad de hacer click en iconos. Todo lo que vemos en windows, el escritorio, las carpetas, la barra de start etc es parte del explorer. Explorer.exe, es la tipica, fallaba esto y se iba toda la interfaz de windows excepto los programas abiertos porque claro no eran parte de explorer. Entonces, explorer en si no es el sistema operativo, es simplemente un programa que viene con el. A lo que realmente es el SO, es a lo que se le llama kernel. El kernel es la parte fundamental de Windows que provee la API para las tareas que requieren interacciones.
En Linux se da la misma distincion, el kernel es lo que provee los servicios e interfaces a traves de una API, mientras que los shells (como bash) son programas, o tambien los ambientes de escritorios (que mal suena en castellano, los Desktop Environments) son prgoramas de interfaz grafica como KDE y GNOME.
Middleware
Ya tocamos la palabra API, que se usa un montón en web dev, sobre todo para APIs HTTP, pero ¿y el middleware?
El middleware es software que, como su nombre indica, está en el medio. En el medio entre una aplicación y un sistema operativo.
Los sistemas operativos y los middlewares tienen bastante en común. Ambos sirven para dar soporte a otros softwares, los dos ofrecen un rango similar de servicios centrados en interacciones controladas, y, al igual que un sistema operativo, el middleware también puede establecer reglas para evitar que una tarea interfiera con otra.
Pero ojo, MW y SO no son lo mismo. El middleware depende de diferentes proveedores de bajo nivel. En cambio, el sistema operativo provee sus servicios a través de su API, usando las características ofrecidas por el hardware.
Ejemplo: el SO puede ofrecer servicios API para leer y escribir archivos usando el disco duro y su capacidad de escribir bloques de data de longitud fija. El middleware, por su parte, puede ofrecer servicios API para escribir tablas en una base de datos, usando a su vez la API del SO, que termina escribiendo archivos que forman la base de datos.
Este layout de capas, es decir la capa del middleware que esta por encima del sistema operativo pero por debajo de los programas explica el por que del nombre. Es la capa intermedia.
Multiples tareas en una computadora
El principio más fundamental de un sistema operativo es que permite correr varias tareas a la vez, sin necesidad de esperar a que cada una termine para ejecutar la siguiente. Esto hace posible que las computadoras corran varios programas al mismo tiempo y, por ejemplo, que puedan responder a múltiples requests de red simultáneamente. Pero el beneficio no es solo la concurrencia, sino también un uso más eficiente de los recursos. Por ejemplo, mientras una tarea está esperando un input (de cualquier tipo), la PC puede seguir usando el procesador para ejecutar otra tarea.
Se usan muchas palabras para describir estas computaciones. Yo estuve usando "tarea" (task), pero también se pueden llamar threads (hilos), procesos o trabajos. Depende del contexto, porque aunque parezcan lo mismo, no lo son.
Un hilo (thread) es la unidad fundamental de la concurrencia. Cualquier secuencia de acciones programadas es un hilo. Ejecutar un programa puede requerir múltiples hilos si necesita correr varias secuencias de acciones en paralelo.
Incluso si un programa solo genera un hilo, lo común es que el sistema operativo esté ejecutando múltiples hilos al mismo tiempo: uno para cada programa en ejecución y otros para ciertas partes del propio sistema operativo
Cuando arrancamos un programa estanis suenore creando uno o mas hilos. Pero tambien estamos creando un proceso. El prcoeso es un contenedor que alberga el hilo o los hilos que arrancaste a correr y los protege de interacciones no deseadas con otros hilos que corren a la vez en la misma computadora. Por ejemplo, un hilo corriendo en un proceso no puede escribir accidentalmente la memoria en uso de otro proceso.
Como los humanos normalmente inician un nuevo proceso cada vez que quieren ejecutar una nueva computación, es fácil caer en la idea de que el proceso es la unidad de ejecución concurrente. Esta idea se refuerza porque en sistemas operativos más antiguos cada proceso tenía exactamente un solo hilo, así que ambos conceptos estaban ligados uno a uno y no hacía falta diferenciarlos.
Cuando hable de la capacidad de iniciar una secuencia independiente de acciones programadas, voy a referirme a la creación de hilos. Y cuando hable de la capacidad de proteger hilos, voy a referirme a la creación de procesos.
Para poder dar soporte a los hilos, los apis de los sistemas operativos pueden crear nuevos hilos y matar hilos existentes. Dentro del SO, tiene que haber un mecanismo para cambiar el foco de la atencion de la computadora entre los varios hilos. Cuando el sistema operativo suspende la ejecucion de un hilo para darle paso a otro hilo, el sistema operativo debe almacenar la suficiente informacion sobre el primer hilo para poder retomar su actividad en un tiempo posterior.
Algunos hilos puede que no sean ejecutables en un tiempo posterior dado que esten esperando a un input, pero en general, un sistema operativo va a tener muchos hilos por correr y va tener que elegir cual ejecutar en cada momento. Este problema de ejecutar hilos (schedule threads) tiene muchas soliuciones posibles y es un problema interesante porque involucra diversos balances que el sistema tiene que hacer entre los intereses del usuario y los recursos del sistema.
Interacciones entre computos
Correr varios hilos a la vez se vuelve mucho más interesante cuando los hilos tienen que interactuar entre sí en lugar de ejecutar tareas independientes. Por ejemplo, un hilo puede estar produciendo datos y otro consumiéndolos. Si un hilo está escribiendo en memoria y el otro está leyendo, no querés que el que lee se adelante al que escribe y empiece a leer direcciones de memoria que todavía no fueron escritas. Esto es solo un ejemplo de lo que puede pasar. En esencia, se trata de controlar el tiempo relativo de ejecución de los hilos.
Más adelante voy a cubrir distintos patrones de sincronización, incluyendo cómo mantener un consumidor sincronizado sin que se adelante al productor, y los mecanismos que suelen usarse para esta sincronización. Algunos de estos mecanismos los ofrece directamente el sistema operativo, mientras que otros requieren bastante middleware.
También voy a hacer hincapié en lo complicado que puede volverse el uso de la sincronización. Si un hilo tiene que esperar al otro para avanzar, ¿qué pasa si el segundo hilo también está esperando al primero? Deadlock. Para evitarlo, se suele recurrir bastante al middleware. Las bases de datos, por ejemplo, tienen una forma interesante de lidiar con el problema del deadlock.
Cuando dos cómputos corren en paralelo en una misma computadora, el desafío de controlar la interacción entre ellos está en mantener esa interacción bajo control. Siguiendo el ejemplo anterior de los dos hilos, donde uno produce datos y el otro los consume, no hay mucho misterio en cómo los datos fluyen entre ambos, ya que están usando la misma memoria de la computadora. Lo difícil es regular el uso de esa memoria compartida.
Threads - hilos
Los programas de una computadora se componen de instrucciones, y las computadoras llevan a cabo pasos especificados por esas instrucciones. Esas secuencias de pasos computacionales que se ejecutan unas tras otras se llaman hilos.
Los programas más simples que pueden escribirse son los de un solo hilo (single-threaded), con instrucciones que se ejecutan una tras otra en una sola secuencia.
Hay que diferenciar entre programa e hilo; el programa contiene instrucciones, mientras que el hilo consiste en la ejecución de esas instrucciones. Incluso para los programas de un solo hilo, esta distinción importa. Si un programa contiene un bucle (loop), entonces un programa corto podría generar un hilo largo de ejecución. Además, ejecutar el mismo programa diez veces crearía diez hilos, todos ejecutando el mismo programa.

Cada hilo tiene un tiempo de vida, que se extiende desde la ejecución de la primera instrucción hasta el momento en que se ejecuta la última instrucción. Si dos hilos tienen tiempos de vida que se solapan, se llaman hilos concurrentes (concurrent).
Uno de los objetivos fundamentales de los sistemas operativos es permitir que múltiples hilos se ejecuten de manera concurrente en la misma computadora. Es decir, en vez de esperar a que el primer hilo termine para ejecutar un segundo, debería ser posible dividir la "atención" de la computadora entre ambos.
Si la computadora tiene múltiples procesadores, entonces naturalmente será posible ejecutar hilos de forma concurrente, uno por procesador. Sin embargo, los usuarios del sistema operativo generalmente querrán ejecutar más hilos de manera concurrente que el número de procesadores disponibles, por lo que el sistema operativo debe dividir la atención del procesador entre múltiples hilos.
A continuación, se hará foco en el caso en que todos los hilos se ejecuten bajo un solo procesador, salvo que se mencione lo contrario.
Ejemplos de programas multi-hilos
Siempre que un programa empieza a correr la computadora lleva acabo las instrucciones en un solo hilo. Dicho esto, si el programa esta armado para correr en multiples hilos, el hilo original en algun punto va crear un hilo hijo. (Spawn a child thread). Este hilo hijo va llevar a cabo algunas acciones mientras el hilo padre lleva a cabo otras. Para mas de dos hilos, el programa puede repetir el proceso de creacion de hilos. La mayoria de los lenguajes de programacion tienen una API para hilos que incluye una manera de crear un hilo hijo. Realisticamente, los programas multi-hilos requieren un control fino de la interaccion entre hilos. Los ejemplos a continuacion van a ser simples, en JAVA.
El ejemplo a continuacion muestra un programa multihilo. El programa principal primero crea un objeto Thread llamado childThread. El objeto Runnable asociado con el hilo hijo tiene un método run que duerme durante tres segundos (expresado como 3000 milisegundos) y luego imprime un mensaje. Este método run comienza a ejecutarse cuando el procedimiento principal invoca childThread.start().
Como el método run se ejecuta en un hilo separado, el hilo principal puede continuar con los pasos siguientes, durmiendo cinco segundos (5000 milisegundos) e imprimiendo su propio mensaje.
public class Simple2Threads {
public static void main(String[] args) {
Thread childThread = new Thread(new Runnable() {
@Override
public void run() {
sleep(3000);
System.out.println("Child is done sleeping 3 seconds.");
}
});
childThread.start();
sleep(5000);
System.out.println("Parent is done sleeping 5 seconds.");
}
private static void sleep(int milliseconds) {
try {
Thread.sleep(milliseconds);
} catch (InterruptedException e) {
// Ignore this exception; it won't happen anyhow
}
}
}
Motivos para usar hilos concurrentes
Con este ejemplo pudimos ver como la ejecucion de un solo programa puede resultar en mas de un hilo. Mas alla de como se ejecuta la creacion de hilos, hay un pregunta a responder, porque deberiamos quere ejecutar varios hilos de manera concurrente en vez de esperar a que uno termine para crear el siguiente. Fundamentalmente, la mayoria de las veces se debe a dos cosas:
Capacidad de respuesta: permitir que el sistema informático responda rápidamente a algo externo al sistema, como un usuario humano u otro sistema informático. Incluso si un hilo está en medio de un cálculo largo, otro hilo puede responder al agente externo. Nuestro programa de ejemplo ilustraron la capacidad de respuesta: tanto el hilo padre como el hilo hijo respondieron a un temporizador.
Uso de recursos: mantener la mayoría de los recursos de hardware ocupados la mayor parte del tiempo. Si un hilo no necesita una parte particular del hardware, otro puede hacer un uso productivo de ella.
Estos dos motivos tendrán muchas variaciones; veremos algunas más adelante. Un tercer motivo por el cual los programadores pueden querer usar hilos concurrentes es para modularizar. Es decir, se pueden crear sistemas complejos descompuestos en varios grupos de hilos que interactúan entre sí.
Un caso de estudio podría ser el de un servidor web, el cual provee a muchos clientes (computadoras que acceden a la web) distintas páginas a través de internet. Cuando un cliente hace una petición al servidor, le envía varios bytes de información que contienen, entre otras cosas, el nombre de la página a la que quiere acceder.
Antes de que el servidor pueda responder, necesita leer esos bytes, generalmente usando un bucle que continúa leyendo desde la conexión hasta detectar el fin de la petición. Supongamos que uno de los clientes se conecta con una conexión lenta; el servidor quizás lea la primera parte de la petición y luego tenga que esperar un tiempo considerable hasta que llegue el resto de los datos por la web desde ese cliente.
¿Qué pasa mientras tanto con el resto de los clientes que quieren enviar sus peticiones? Sería inaceptable que todo el servidor quede detenido, sin poder atender a otros clientes, solo por esperar a que termine la transferencia de un cliente lento.
Una manera en que los servidores prevén y evitan esta situación es usando múltiples hilos, uno para cada cliente y cada conexión. De esta forma, si un hilo está esperando, otros hilos pueden continuar interactuando con otros clientes.
Desde el lado del cliente, un navegador web también puede ilustrar el concepto de capacidad de respuesta. Imaginá que comenzás a cargar una página bastante pesada que tarda mucho tiempo en descargarse. ¿Te gustaría que la computadora se congele hasta que termine de descargar la página? Probablemente no; esperarías poder seguir haciendo otras cosas mientras el sitio termina de cargarse.

Pasando al foco de la utilización de recursos, el escenario más obvio es, quizás, cuando tenés una computadora con más de un procesador. En ese caso, si el sistema ejecutara solo un hilo a la vez, la mitad de los recursos quedarían sin utilizar. Aunque el usuario no necesite realizar más de una acción al mismo tiempo, hay ciertas tareas de mantenimiento interno que la computadora podría llevar a cabo para mantener el segundo procesador ocupado.
Incluso en sistemas de un solo procesador, la utilización de recursos puede justificar el uso de hilos concurrentes. Imaginá que querés escanear tu PC para ver si tiene virus mientras hacés un render fotorealista. Sabés que cada operación por separado lleva una hora; si ejecutás una y luego la otra, el tiempo total sería de dos horas. Ahora bien, si probás ejecutar ambas a la vez, quizás te lleves la sorpresa de que se completan en una hora y media.
La explicación para el ahorro de esa media hora es que, al escanear archivos, el programa pasa la mayor parte del tiempo accediendo al disco duro, leyendo archivos, con solo algunos picos esporádicos de uso de CPU cada vez que se termina de leer un archivo. En cambio, el programa de renderizado utiliza casi todo el tiempo el CPU, con muy poco acceso al disco. Si ejecutás ambos procesos en secuencia, una parte de la computadora quedaría inactiva durante largos periodos. Sin embargo, al correrlos simultáneamente, tanto el disco duro como el procesador se mantienen activos todo el tiempo, incrementando así la eficiencia total del sistema.
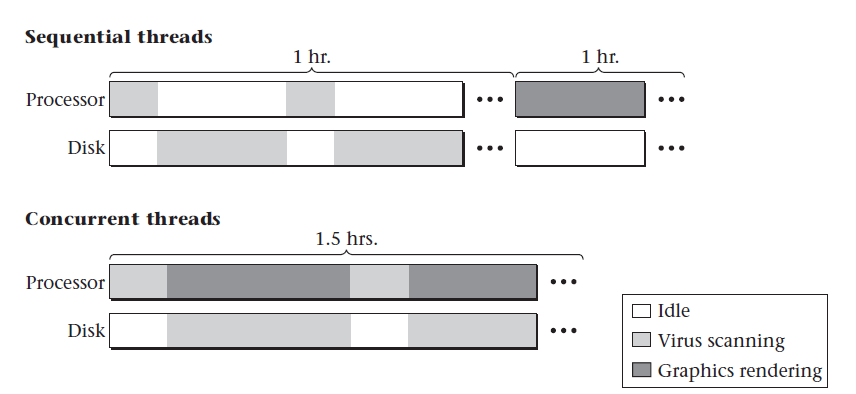
Claro está, esto asume que el scheduler del sistema operativo es lo suficientemente inteligente como para saber cuándo cambiar el foco del CPU del render al escaneo de virus cada vez que se termina la lectura de un archivo.
Como hemos visto, los hilos pueden originarse en múltiples fuentes y tener diversos roles. Pueden ser partes internas del sistema operativo o formar parte de aplicaciones de software del usuario. Sin importar de dónde provengan, las razones típicas para ejecutar hilos de manera concurrente siguen siendo las mismas: capacidad de respuesta y eficiencia del sistema.
Cambiando de hilos
Para que el sistema operativo pueda tener más de un hilo corriendo en el procesador, necesita un mecanismo que le permita cambiar el foco entre ellos. En particular, debe poder interrumpir la ejecución de un hilo en medio de su secuencia de instrucciones, trabajar en otros hilos y luego volver para continuar desde donde había dejado.
Para explicar esto de la forma más simple posible, vamos a asumir que cada hilo está ejecutando código que, de vez en cuando, incluye instrucciones explícitas para ceder el control a otro hilo. Una vez que entendamos bien cómo funciona este mecanismo en este escenario, podemos analizar casos más realistas en los que el hilo no contiene estas instrucciones y es interrumpido automáticamente para cambiar de contexto.
Supongamos que tenemos dos hilos, A y B, y que usamos A1, A2, A3, etc., para referirnos a las instrucciones del hilo A, y B1, B2, B3, etc., para las del hilo B.
En este caso, una posible secuencia de ejecución podría ser la siguiente:
HILO A
HILO B
A1
A2
A3
switchFromTo(A, B)
B1
B2
B3
switchFromTo(B, A)
A4
A5
switchFromTo(A, B)
B4
B5
B6
B7
switchFromTo(B, A)
A6
A7
A8
switchFromTo(A, B)
B8
B9
Para que el sistema operativo pueda cambiar de hilo, necesita mantener información sobre el estado de cada uno, como la posición exacta desde la cual debe retomar la ejecución. Si esta información se guarda en un bloque de memoria específico para cada hilo, podemos usar la dirección de esos bloques para referirnos a los hilos. Cada bloque de memoria que contiene esta información se llama TCB (Thread Control Block). Por lo tanto, otra manera de decir que usamos las direcciones de memoria de estos bloques es que utilizamos pointers al TCB del hilo correspondiente.
Nuestro mecanismo fundamental para cambiar de hilos será el método switchFromTo, el cual toma como parámetros dos de estos TCB (Thread Control Block): uno que especifica desde qué hilo estamos cambiando y otro que indica hacia cuál hilo cambiamos. En el ejemplo anterior, A y B son punteros que apuntan a los TCB de los respectivos hilos A y B, y los usamos para alternar entre el hilo saliente y el entrante.
Por ejemplo, el programa del hilo A, después de la instrucción A5, tiene código que indica cambiar de A a B, y el hilo B tiene código después de B3 para cambiar de B hacia A. Esto asume que cada hilo conoce su propia identidad y también la del hilo al que debe transferir el control. Más adelante veremos cómo eliminar esta premisa, que no es del todo realista.
Por ahora, enfoquémonos en cómo podría escribirse el método switchFromTo para que switchFromTo(A, B) guarde el estado de ejecución al cambiar de A a B, permitiendo que, al retomar la ejecución de B a A, el hilo continúe desde donde se había detenido.
Ya vimos que la información de estado que se debe guardar no solo incluye la posición en el programa, conocida como Program Counter (PC) o Instruction Pointer (IP), sino también el contenido de los registros (registers).
Otra parte crítica del estado de ejecución, especialmente en programas compilados con la mayoría de los lenguajes de alto nivel, es el stack (pila). El stack almacena información como variables locales, direcciones de retorno y otros datos necesarios para la ejecución de funciones. Para gestionar el stack, cada hilo utiliza un registro puntero de stack (Stack Pointer Register), que indica la posición actual en memoria de la cima del stack.
Cuando un hilo retoma la ejecución, debe encontrar el stack exactamente como lo dejó. Por ejemplo, imaginemos que el hilo A coloca dos elementos en su stack y luego se pausa mientras el hilo B se ejecuta. Al retomar la ejecución, A debería encontrar esos dos elementos intactos en su stack, incluso si B también utilizó su propio stack durante ese tiempo. Esto se logra dándole a cada hilo su propio stack, reservando una porción de memoria independiente para cada uno.
Cuando A se está ejecutando, su Stack Pointer (SP) apunta a algún lugar dentro del área de memoria reservada para el stack de A, indicando cuánto espacio está ocupado. Al cambiar al hilo B, debemos guardar el stack pointer de A junto con los demás registros. Mientras B se ejecuta, su propio stack pointer se moverá dentro del área de memoria asignada a B, de acuerdo con las operaciones de push y pop que realice.
Habiendo establecido que necesitamos mantener distintos stacks y pointers, podemos simplificar el guardado de todos los demas registros metiendolos en el stack justo antes de cambiar de hilo, y sacandolos del stack justo luego de volver al hilo. Podemos usar este approach para marcar en el codigo cuando salimos y vamos al proximo hilo usando outgoing y next como los dos punteros al TCB.
Cuando cambiamos de A a B, outgoing seria A y next seria B. Luego al cambiar de B a A, outgoing seria B y nextseria A.
Con estas bases, nuestro codigo tendria la siguiente forma general:
- Apilar cada registro en el stack (del hilo saliente)
- Guardar el puntero de stack en
saliente->SP - Cargar el puntero de stack desde
siguiente->SP - Guardar la dirección de la etiqueta L en
saliente->IP - Cargar
siguiente->IPy saltar a esa dirección - L:
- Desapilar cada registro del stack (del hilo saliente cuando se reanuda)
Hay que notar que el código antes de la etiqueta (L) se ejecuta en el momento de cambiar desde el hilo saliente, mientras que el código después de esa etiqueta se ejecuta más tarde, al reanudar la ejecución cuando otro hilo cambia de vuelta al hilo original.
Este código no solo guarda el puntero de stack del hilo saliente, sino que también restaura el puntero de stack del siguiente hilo. Más adelante, el mismo código se usará para cambiar de vuelta. Por lo tanto, podemos contar con que el puntero de stack del hilo original habrá sido restaurado cuando el control salte a la etiqueta L. Así, cuando los registros se desapilen, se hará desde el stack del hilo original, coincidiendo con las operaciones de push al inicio del código.

Podemos ver cómo este patrón se implementa en un sistema real si observamos el código de cambio de hilos en Linux para la arquitectura i386.
Este código es real, extraído del kernel de Linux, aunque se han eliminado algunas complicaciones periféricas para simplificarlo. El registro del stack pointer se llama %esp, y cuando el código comienza a ejecutarse, los registros %ebx y %esi contienen los punteros outgoing y next, respectivamente. Cada uno de estos punteros es la dirección de un TCB (Thread Control Block). La ubicación en el offset 812 dentro del TCB contiene la dirección de instrucción del hilo (es decir, el IP), y la ubicación en el offset 816 contiene el stack pointer (SP).
pushfl # Guarda los flags en el stack del hilo saliente (outgoing)
pushl %ebp # Guarda %ebp en el stack del hilo saliente
movl %esp, 816(%ebx) # Guarda el stack pointer del hilo saliente en el TCB
movl 816(%esi), %esp # Carga el stack pointer del siguiente hilo desde su TCB
movl $1f, 812(%ebx) # Guarda la dirección de la etiqueta 1,
# donde el hilo saliente reanudará
pushl 812(%esi) # Guarda la dirección de instrucción
# donde el siguiente hilo reanudará
ret # Extrae la dirección de instrucción y salta a ella
1:
popl %ebp # Al reanudar el hilo saliente más tarde, restaura %ebp
popfl # Restaura los flags
Este código muestra cómo el sistema guarda y restaura tanto el estado de los registros como las posiciones en el stack, permitiendo que los hilos se suspendan y reanuden de manera correcta.
code explanation:
Contexto general:
- %ebx contiene el puntero al TCB del hilo saliente (outgoing).
- %esi contiene el puntero al TCB del siguiente hilo que será ejecutado (next).
- %esp es el stack pointer que indica la posición actual en la pila.
- %ebp es el base pointer, usado como referencia para el acceso a variables locales y parámetros dentro de una función.
- pushfl/popfl son instrucciones que guardan/restauran los flags del procesador, que contienen información sobre el estado de la CPU (como si la última operación resultó en cero, si hubo un desbordamiento, etc.).
Desglose línea por línea:
-
pushfl
Guarda los flags en el stack del hilo saliente (outgoing)-
¿Qué hace?
Esta instrucción empuja el contenido del registro de flags al stack. Los flags incluyen información como el estado de las operaciones aritméticas, el bit de interrupciones, etc. Es importante guardarlos para que, cuando el hilo se reanude, el estado de la CPU sea exactamente el mismo que antes de la suspensión. -
¿Por qué es importante?
Si no guardás los flags, al reanudar el hilo podrías tener comportamientos inesperados, ya que la CPU podría interpretar mal el resultado de operaciones previas.
-
-
pushl %ebp
Guarda %ebp en el stack del hilo saliente-
¿Qué hace?
El registro%ebpse utiliza como base pointer en la pila, marcando el inicio del marco de pila de la función actual. Guardarlo asegura que, al volver a este hilo, la estructura de la pila esté intacta y las variables locales sean accesibles correctamente. -
¿Por qué es importante?
Preservar%ebppermite que las funciones puedan continuar ejecutándose como si nunca hubieran sido interrumpidas.
-
-
movl %esp, 816(%ebx)
Guarda el stack pointer del hilo saliente en el TCB-
¿Qué hace?
El valor actual de%esp, que apunta al tope de la pila del hilo saliente, se guarda en el TCB del hilo saliente en el offset 816. Esto guarda la posición exacta en la pila para poder reanudar más tarde. -
¿Por qué es importante?
Al reanudar el hilo saliente, el sistema sabrá exactamente dónde estaba el stack y podrá restaurarlo para que la ejecución continúe sin errores.
-
-
movl 816(%esi), %esp
Carga el stack pointer del siguiente hilo desde su TCB-
¿Qué hace?
Se recupera el stack pointer guardado del siguiente hilo (almacenado en el TCB en el offset 816) y se carga en%esp. Ahora el procesador está listo para usar la pila del hilo siguiente. -
¿Por qué es importante?
Cambiar el stack pointer al del siguiente hilo asegura que cualquier operación de la pila (como llamadas a funciones o manipulación de variables locales) afectará al nuevo hilo y no al anterior.
-
-
movl $1f, 812(%ebx)
Guarda la dirección de la etiqueta 1 en el TCB del hilo saliente-
¿Qué hace?
La instrucción guarda la dirección de la etiqueta1en el TCB del hilo saliente en el offset 812. Esta dirección actúa como un marcador de dónde debe continuar la ejecución cuando el hilo saliente sea reanudado. -
¿Por qué es importante?
Sin esta dirección, el hilo saliente no sabría dónde continuar su ejecución, lo que podría llevar a un comportamiento errático o a una corrupción de la memoria.
-
-
pushl 812(%esi)
Guarda la dirección de instrucción donde el siguiente hilo reanudará-
¿Qué hace?
La dirección de instrucción donde el siguiente hilo debe continuar (almacenada en el offset 812 de su TCB) se empuja a la pila. Este valor es el Instruction Pointer (IP) del siguiente hilo. -
¿Por qué es importante?
Esto permite que, al ejecutar la instrucciónret, el procesador sepa a qué dirección exacta debe saltar para reanudar la ejecución del siguiente hilo.
-
-
ret
Extrae la dirección de instrucción de la pila y salta a ella-
¿Qué hace?
La instrucciónretsaca la dirección de instrucción de la pila (que fue colocada ahí en la línea anterior) y transfiere el control del CPU a esa dirección, efectivamente cambiando la ejecución al siguiente hilo. -
¿Por qué es importante?
retes la instrucción que finaliza el cambio de contexto y comienza la ejecución del siguiente hilo.
-
Reanudando el hilo original:
Cuando eventualmente se cambie de vuelta al hilo original (outgoing), la ejecución continuará desde la etiqueta 1. En ese momento, es necesario restaurar los registros y flags que se guardaron antes de suspender el hilo.
-
1:
Etiqueta donde el hilo saliente reanuda su ejecución- Esta es la dirección guardada anteriormente en
812(%ebx). Cuando otro hilo decide devolver el control al hilo original, la ejecución continuará desde aquí.
- Esta es la dirección guardada anteriormente en
-
popl %ebp
Restaura %ebp al reanudar el hilo saliente- ¿Qué hace?
Recupera el valor original de%ebpdel stack, asegurando que el marco de pila esté restaurado correctamente para las funciones que estaban en ejecución antes del cambio de contexto.
- ¿Qué hace?
-
popfl
Restaura los flags al reanudar el hilo saliente- ¿Qué hace?
Recupera los flags de la CPU del stack, devolviendo el estado de la CPU al momento exacto antes de la interrupción.
- ¿Qué hace?
Resumen del proceso:
-
Antes del cambio de hilo (context switch):
- Guardás los registros críticos y el estado de la CPU (flags).
- Guardás el stack pointer y la dirección de instrucción en el TCB del hilo saliente.
- Restaurás el stack pointer y la dirección de instrucción del siguiente hilo.
- Saltás a la ejecución del siguiente hilo.
-
Al reanudar un hilo:
- Restaurás el stack pointer y los registros del hilo.
- Recuperás el estado exacto de la CPU (flags).
- Continuás ejecutando desde donde el hilo fue interrumpido.
Ahora que entendimos la idea principal de cómo un procesador cambia de un hilo en ejecución a otro, podemos eliminar la suposición de que cada hilo necesita conocer explícitamente los nombres del hilo saliente (outgoing) y del entrante (next). Es decir, queremos alejarnos de la idea de que debemos identificar a los hilos como A y B para poder realizar el cambio.
Es fácil saber de qué hilo estamos cambiando si simplemente mantenemos un registro actualizado del hilo que está corriendo en todo momento. Esto se puede lograr guardando un puntero al TCB del hilo actual en una variable global llamada current.
Esto nos deja con la pregunta de cómo se elige el siguiente hilo a ejecutar. Para resolverlo, el sistema operativo debe llevar un registro de todos los hilos disponibles en alguna estructura de datos, como una lista. A partir de esto, se implementa un procedimiento llamado chooseNextThread(), que consulta dicha estructura y, utilizando alguna política de scheduling, decide cuál será el siguiente hilo a correr.
Más adelante veremos cómo implementar este mecanismo, pero por ahora podemos resumirlo en un procedimiento llamado yield(), que realiza los siguientes cuatro pasos:
outgoing = current;
next = chooseNextThread();
current = next; // actualiza la variable global con el nuevo hilo
switchFromTo(outgoing, next);
Ahora, cada vez que un hilo decide pausar su ejecución y permitir que otros hilos corran por un tiempo, simplemente debe invocar yield(). Este enfoque es similar al que adoptan sistemas reales como Linux.
Una complicación en sistemas multiprocesador es que la variable current debe mantenerse de forma independiente por procesador (per-processor basis), ya que cada núcleo puede estar ejecutando un hilo diferente.
El proceso de cambiar de un hilo a otro se conoce comúnmente como cambio de contexto (context switching), porque se cambia el contexto de ejecución de un hilo por el de otro.
MULTITAREA PREEMPTIVA (Preemptive Multitasking)
Por ahora vimos como podria llevarse a cabo el cambiol de hilos en sistemas que llevan a cabo lo que se llamaria multi-tasking cooperativo, donde el programa de cada hilo tiene codigo explicito de en que punto deberia cambiar de hilos.
Algo mas realista en los sistemas operativos es lo que se llama preemptive multitasking, donde el codigo del programa no tiene nada sobre thread switching, sinembargo el cambio de hilos pasa mas o menos de manera automatica de vez en cuando.
Una razón para preferir esta manera de cambiar de hilos es que el código con errores (bugs) en un hilo no alterará la ejecución del resto. Por ejemplo, consideremos un bucle que se espera que corra una cierta cantidad de veces. En un sistema multitarea, parecería seguro realizar el cambio de hilos antes o después del bucle, en lugar de hacerlo dentro del cuerpo del bucle. Sin embargo, un error podría convertir ese bucle en uno infinito, bloqueando el procesador para siempre. Con la multitarea preemptiva, el hilo podría ejecutarse indefinidamente, pero al menos, de vez en cuando, se detendría para permitir que otros hilos progresen.
Otra razón para usar la multitarea preemptiva es permitir que el cambio de hilos ocurra cuando mejor se cumplan los objetivos de capacidad de respuesta y uso eficiente de los recursos. Por ejemplo, el sistema operativo puede prever cuándo ejecutar un hilo que está en espera o cuándo utilizar un componente de hardware que no está siendo usado.
Incluso con multitarea preemptiva, puede ser útil que un hilo, ocasionalmente, ceda voluntariamente el control a otros hilos en lugar de ejecutarse hasta que el sistema operativo lo interrumpa. Por eso, los sistemas que funcionan de esta manera también incluyen una función como yield(). El nombre puede variar según la API, pero generalmente incluye el término yield.
La multitarea preemptiva no requiere ningún mecanismo fundamentalmente diferente para el cambio de hilos; solo necesita un sistema de interrupciones de hardware (hardware interrupts).
Normalmente, un procesador ejecuta las instrucciones de forma consecutiva, una tras otra, desviándose de este flujo solo cuando existe una instrucción explícita de salto (jump). Sin embargo, hay otro mecanismo mediante el cual el hardware externo (como un disco duro o una tarjeta de red) puede señalar que necesita atención. Un temporizador de hardware (hardware timer) también puede requerir atención de forma periódica, por ejemplo, cada milisegundo.
Cuando un sistema de E/S (I/O) o un temporizador necesita atención, ocurre una interrupción (interrupt), lo que equivale a que un conjunto de instrucciones se inserte de forma forzada entre las instrucciones que se están ejecutando y las que vendrían a continuación. En lugar de continuar con la ejecución normal, se ejecuta el código forzado, conocido como el manejador de interrupciones (interrupt handler).
El interrupt handler es parte del sistema operativo, se encarga de gestionar los dispositivos de hardware y ejecuta una instrucción de retorno de la interrupción (return from interrupt) cuando finaliza, reanudando la instrucción que estaba por ejecutarse antes de que ocurriera la interrupción. Es importante aclarar que, para que esto funcione correctamente, el interrupt handler debe ser cuidadoso: debe guardar todos los registros al comienzo de su ejecución y restaurarlos al finalizar.
Usando este mecanismo de interrupciones, un sistema operativo puede ofrecer multitarea con preempción (preemptive multitasking). Cuando ocurre una interrupción, el manejador de interrupciones primero guarda los registros en la pila (stack) del hilo actual y atiende las necesidades inmediatas, como recibir datos de un controlador de interfaz de red o actualizar la hora del sistema en un milisegundo.
Luego, en lugar de simplemente restaurar los registros y ejecutar una instrucción de retorno de interrupción (return from interrupt), el manejador de interrupciones verifica si sería un buen momento para interrumpir (preempt) el hilo actual y cambiar a otro.
Por ejemplo, si la interrupción señala la llegada de datos que un hilo ha estado esperando durante mucho tiempo, podría tener sentido cambiar a ese hilo. O, si la interrupción proviene del temporizador (timer) y el hilo actual ha estado ejecutándose durante un período prolongado, podría ser adecuado darle la oportunidad a otro hilo.
En cualquier caso, si el sistema operativo decide interrumpir el hilo actual, el manejador de interrupciones cambiará de hilo utilizando un mecanismo como el procedimiento switchFromTo. Este cambio de hilos incluye cambiar a la pila del nuevo hilo, por lo que, cuando el manejador de interrupciones restaure los registros antes de regresar, estará restaurando los registros del nuevo hilo.
Los valores de los registros del hilo que se estaba ejecutando previamente permanecerán seguros en su propia pila hasta que dicho hilo sea reanudado.
martín
Dev, maker y eterno aprendiz. Escribo sobre código, infraestructura, herramientas y lo que voy descubriendo en el camino.
Posts relacionados



Comentarios
No hay comentarios todavía. Sé el primero.